How we are designing digger to support multiple CI systems


This is part 1 of a series which discusses how we architected digger cli to support multiple ci systems whilst making the code readable, testable and extendable. We will first discuss how digger was implemented to extend to multiple CI systems and then later we will discuss how we extended it further to support invoking digger on user’s local machines.
Digger is an open source infrastructure automation platform that allows you to run terraform, terragrunt, openTofu and other tools in your CI.
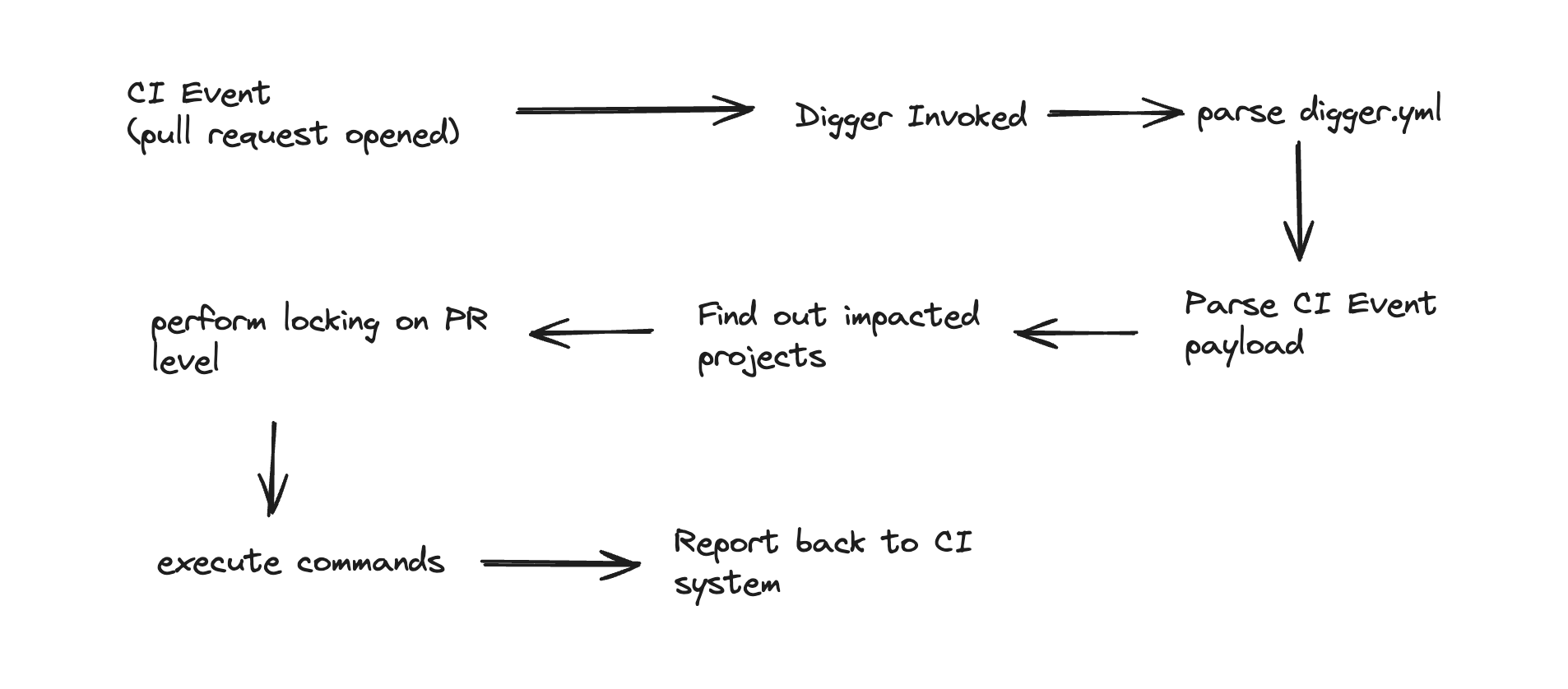
When we started building digger, the core of digger is a cli which is invoked within your ci system. It is responsible for a few tasks to perform after it is invoked. For example consider a user creates a new pull request in their terraform repository:
- Parse event from CI system and extract information such as actor, branch, event type, modified files etc.
- Parse the digger.yml file and convert it to internal digger objects
- Figure out which projects are impacted and what are the commands that need to be executed
- Perform locking for this project for certain event
- Check that the user has access rights to perform this command
- Comment on pull request the result of the command in some
Early on we were faced with an important decision: Do we focus on a single CI system such as Github Actions or also support multiple Ci providers like gitlab, bitbucket and even Jenkins? Our conclusion that while we focus on supporting github for starters we should architect digger to support any other CI system with ease. Digger is entirely written in golang after moving away from Python. In the beginning we decided to focus on CI systems and not worry about having digger working locally. From early design while writing the first lines of code we wanted to ensure that our code has the following qualities:
- Testable: It should be easy to write tests for new and old functionality. Different levels of tests from unit tests to integrations should be acheivable.
- Readable: Since digger is open source and open to contributors this was a key feature of the codebase
- Extensible: Easy for other to add support for their own Ci systems.
These were the key core tenants for our codebase before we got to work!
First iteration: Programming to interfaces
After drafting the first edition we arrived at a pattern of programming to interfaces. Golang interfaces are powerful ways to capture common functionality and easily extend it to other usecases - which is exactly what we needed for the multi CI usecases. The vision was to have all the functionality of CI systems abstracted into one common interface which we arrived at: CIService that interacted with the CI Systems.
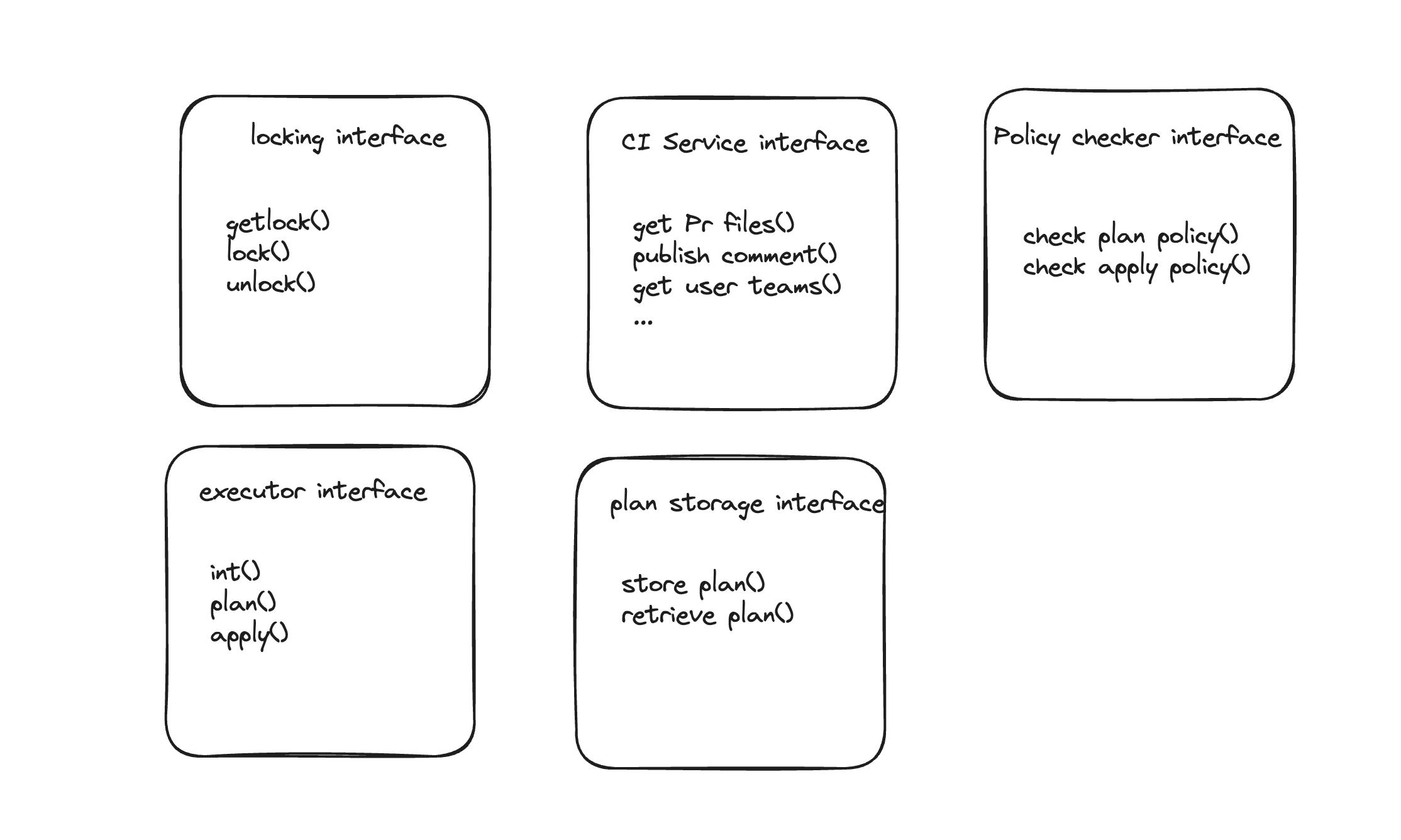
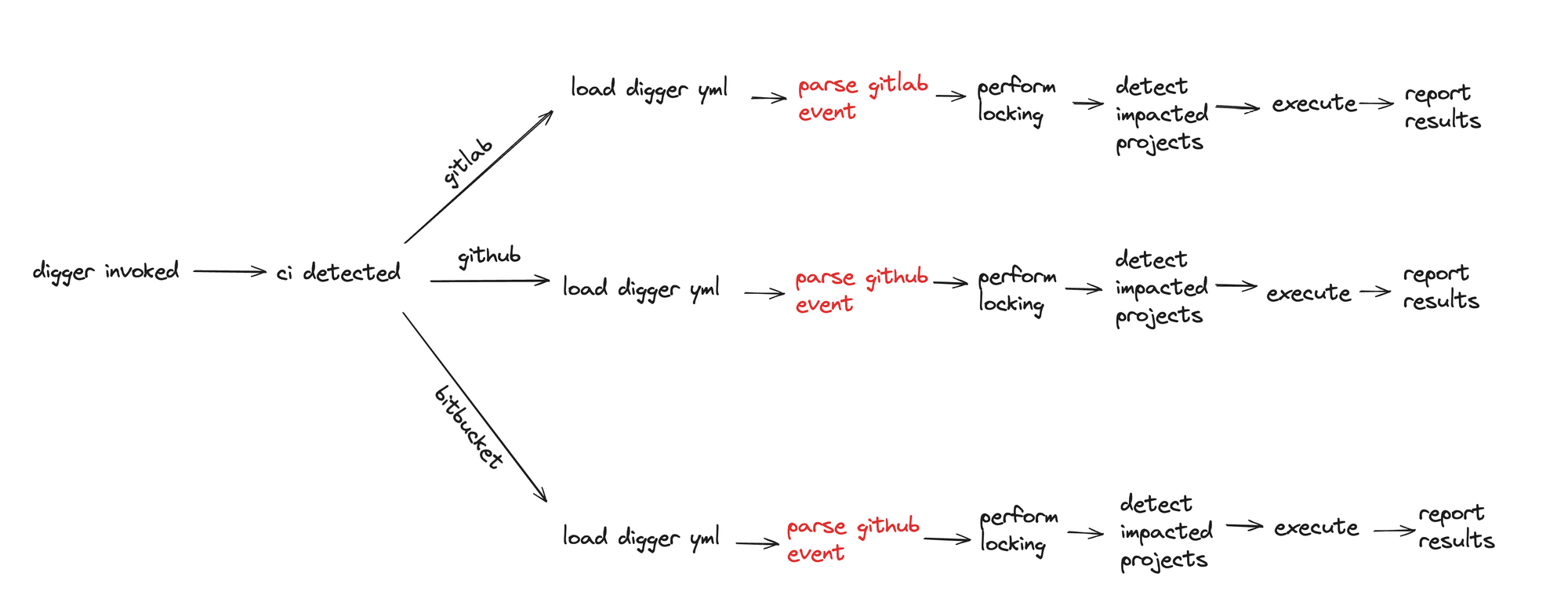
The main logic of the cli then becomes to check for the CI system that triggered the event then load the right interfaces based on the files that have changed:
- Digger loads, initialize main vars
- Detection of CI System
- Based on CI system, go to the right pathway for that system (github, gitlab, bitbucket etc.)
- Within the pathway initialize the right interfaces and figure out the jobs to run
- Then invoke a common “RunJobs” Method which takes a list of jobs, a
CIServiceand invokes the jobs, reporting back to the CISystem based on a reporter.
The advantage of this approach is that there is a single entry point and it is easy to follow through what is going on in a sequencial manner, for every single CI. It also allows mixing and matching between interfaces based on arguments: for example in the locking interface we support dynamoDB locks, google GCP locks, Azure Storage table locks and so on. The disadvantage is that the initial bootstrapping part for every CI is so similar, and ends up being duplicated for every new CI. For example we have the logic of loading the diggerYML, checking for policies, initializing the jobs is shared accross all CI systems yet this logic is duplicated in all the flows. On the bright side, using interfaces such as PRService makes it easy to mix and match accross CI systems but the duplication when it comes to adding another CI is still alot. The question now is can we reduce the duplication accross different CI branches?
Second iteration: Separating the CI payload parsing out from the core of digger
We realised that the main source of code duplication is the branching out between different CI systems. So what if we introduce an additional step of parsing the event coming form CI? This step would translate the event into a generic digger event and pass it onto digger. By designing it in this way there will be only one generic digger flow and multiple parsers that lead to that flow hence minimising the code duplication.
One further benefit of this approach is that we can finally enable local invocation of the cli on user machines, which is a feature that had always been requested but we never got the change to think about how it could work. This is currently being implemented in this WIP pull request
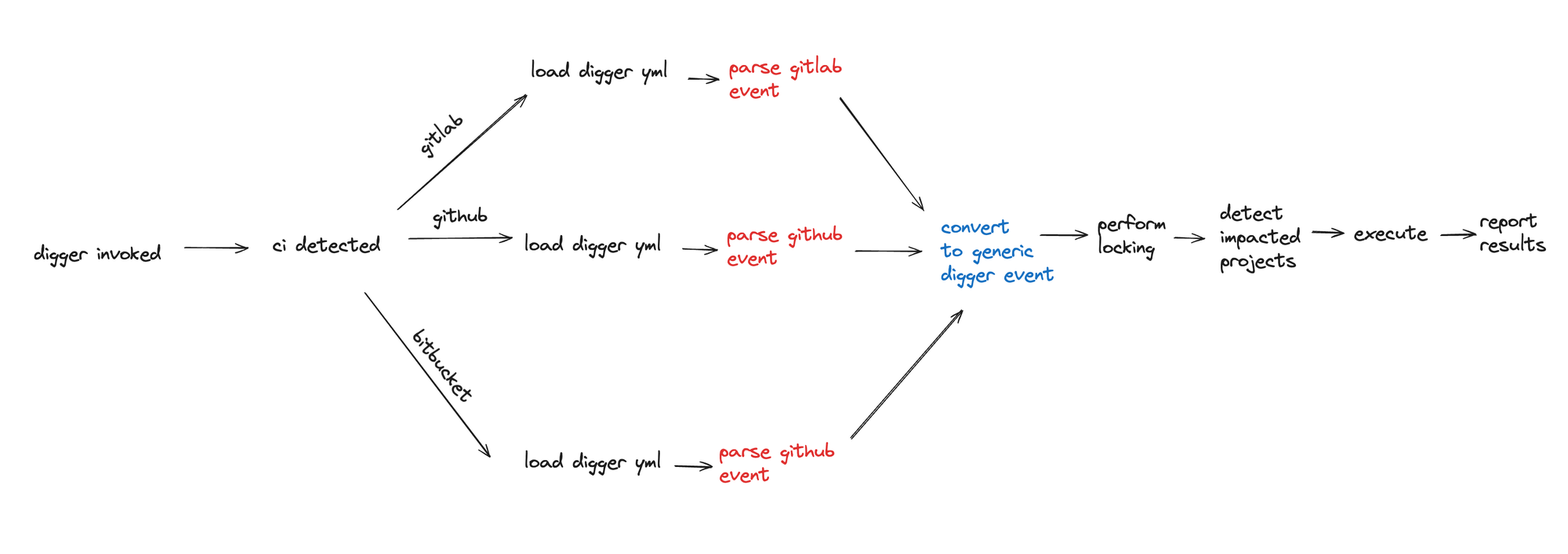
By adding an additional step in the process to convert all events to a generic internal digger event we are able to further reduce any duplications. Now the process of adding a new CI is all about:
- implementing a parser for event
- converter to generic digger CI event
- implementation of interface to interact with CI service
And all of the above can be implemented without touching any of the core flows of digger, a huge improvement from the previous iteration!
Future ideas to improve:
We are also in the process of getting some inspiration from webservers and middlewares. In web frameworks such as express, gin-gonic and others there is a single object “context” that is passed around from the moment and http request is sent and this object is manipulated, also optionally can be passed through several middlewares who can modify and manipulate it. this context is then passed onto the main controller which performs the endpoint logic and passes it it back to the framework indicating the intended response to the user.
The fact that the context is customisable via user middlewares is a very powerful extensability point of webservers. We are looking into the idea of introducing a “Digger context” that is initialized when digger is invoked and then passed into several stages, that are all cusotmisable externally. In a way we have done this by introducing concepts such as Job and DiggerExecutor which are initialized at a later stage, the difference in this approach is that we would have a single object (DiggerContext) initialized when the cli is invoked and this is the only object passed accross several stages from CI detection, parsing, and so on. This would be an extension of the second iteration by introducing customisablity at any point of the pipeline with supporting middleware functions.
In the next part of this series we are going to discuss how we designed digger to have an optional backend that is self hosted, and how we shared common functionality between different flows of the backend and the frontend. Stay tuned!
Digger is an Open Source Infrastructure as Code management platform for Terraform and OpenTofu. Book a demo here if you're keen, or alternatively, join our slack