The case for 'Headless Terraform IDP'

There is a ton of conjecture on who should write the Terraform, and also on the fact that nobody should write it. The problem seems to be time, more specifically, time lost due to blockage of “devs” by “ops” and vice versa. As Leon Wright rightly (see what I did there? :) ) asks - “What’s the answer here? Do we abandon all these tools and go back to a world of Devs doing Dev things and Sys Admins being grumpy gatekeepers?”
The holygrail of a good self service practice involves empowering developers to own their infrastructure, from creation through to deprecation, ensuring compliance with all company standards, requirements and best practices [source]. However, with respect to Terraform specifically, this assumes that all developers know and understand Terraform well enough. We already know that terraform collaboration is not easy and that there is more nuance to using it collaboratively than just knowing it.
At Lyft - they use Atlantis (it’s open source and self-hosted). The reasons they mention include: Workflow customization on a per-team basis, Centralized permissions and binaries, Audit logs in the form of VCS pull requests, Apply guardrails such as PR approvals and mergeability, Opportunities to iterate and contribute features/bug fixes upstream, among others.
So does Doordash. “At DoorDash, the infrastructure code review process is supercharged with policy-as-code through a custom workflow that uses Conftest in Atlantis (DoorDash’s setup predates official OPA support in Atlantis). We self-host Atlantis, which is an open-source golang application for Terraform pull request automation. When a GitHub pull request is created, Atlantis runs a Terraform plan and passes the plan file to Conftest, which then pulls custom policies written in Rego from an AWS S3 bucket, evaluates the OPA policy based on the Terraform plan, then comments the output to the PR — all in a single action”
Many other companies are using IaC specific CI, for similar reasons. Checkout uses spacelift to enable developer self service for Terrafrom, for code reviews and to share Terraform code across multiple teams and organizations. At Pleo on the other hand, they use env0 to solve their drift management issue.
Diving deeper into the OSS use cases at Lyft and Doordash, both of them talk about using Atlantis to set up guardrails to enable self service usage of Terraform in a version controlled manner, to enable audit-ability. This is how it works (from Doordash blog):
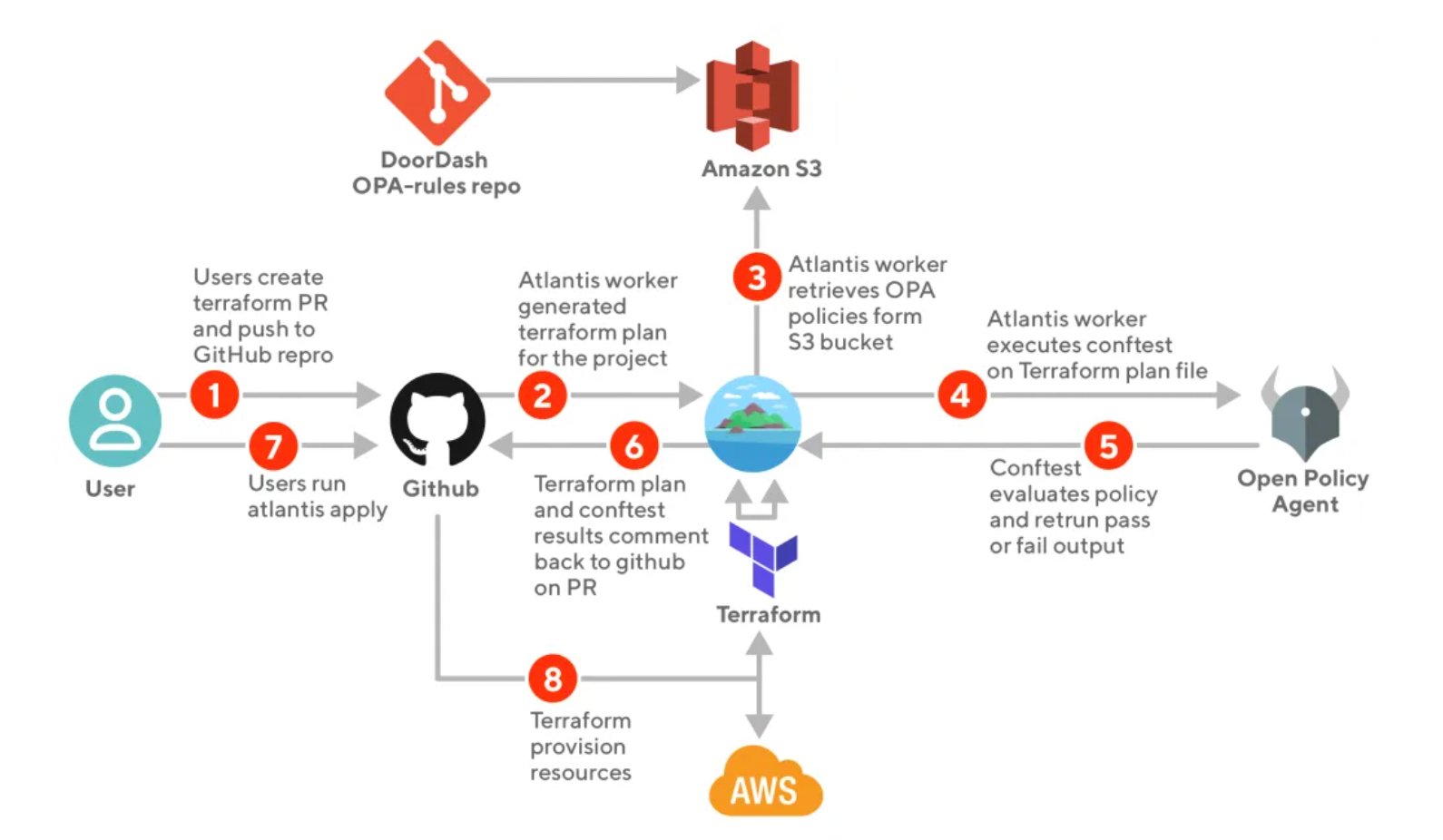
So Atlantis essentially acts as a completely separate CI system. Its workers run the plan (2); then fetch policies (3); then run conftest (4-5); call Github API to add comment (6); and run apply (7). What is it if not steps of a CI pipeline? Except that it’s running on the VM Atlantis is hosted on. Because of that, Lyft felt the need to maintain a fork of Atlantis with Temporal as the backend async jobs backend. And Atlantis’s own configuration for running conftest looks quite similar to Github Actions yaml.
Why have two CI systems?
We started with self-service for Terraform, but somehow arrived at having two separate CI stacks. It seems that the two CI systems act effectively as Internal Developer Platforms (or Portals?) - each with its own UI, orchestration, jobs and compute. Any developer can write Terraform; but what that Terraform can do is controlled by policies, that in turn can only be controlled by few individuals with high enough level of privilege.
IDPs are a recent trend and there are several great products out there in this category, like Backstage by Spotify. The generally accepted meaning of IDP though is more of a service catalog / developer self-service portal. It always implies some kind of UI, typically internal / self-hosted.
But do you actually need the UI? In absence of an IDP, the UI that developers interact with is, unsurprisingly, git and the VCS like github / gitlab. Apart from listing all the services, this scales well even for largest of teams. Both github and gitlab even have UI for role-based access controls to repos. The last missing bit is RBAC aka “who can do what” - but this can be solved via policy-as-code eg OPA (see Doordash use case above).
Let’s say we somehow remove duplication in the CI stacks so that same CI building blocks like compute, jobs, logs etc are reused for both application and infrastructure pipelines. Let’s also say we don’t need a UI for developer self-service, it’s all gitops.
What’s left is a ‘headless IDP’.
This term does not exist, yet. It also doesn’t seem to be perfectly accurate - but I don’t have a better one to describe something that does what IDP does but without a UI. You push to git, and what needs to happen - happens. More importantly, what you don’t want to happen, cannot happen. That combination of policies + runners that bind to a VCS and run the pipelines or stop for manual approval - this is a lot of work to build from scratch, but it doesn’t have to be a UI-first application. Hence, headless IDP.
This is what we are building at Digger - a thin wrapper on top of Terraform that runs natively in your CI’s compute. This is roughly how it works:
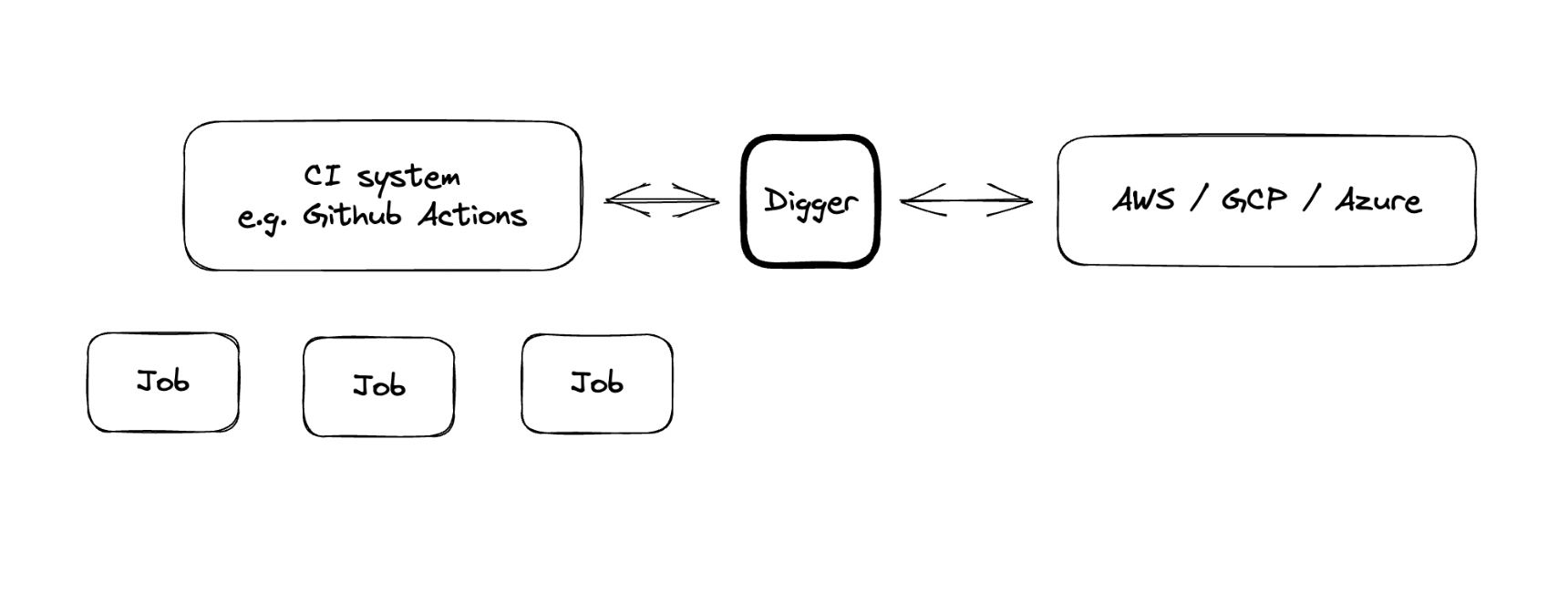
The idea is to have as little “head” as possible, or none at all. No frontend, and optional serverless backend (only needed for CI providers other than GitHub to handle webhooks). The rest can be stored natively in your cloud account using the most appropriate method for each cloud provider, eg DynamoDB for AWS, Storage Buckets on GCP, Storage Tables on Azure. Those pieces are minimal; only needed to support PR-level locks (similar to Atlantis) and store plan artifacts.
If you are considering contributing to Digger - here is a guide.